
最近の医療論文ではmustなデータとなっているICC。
おもに使うのはこの二つ。検者が3名ならICC(3,k)となる
大量計測データをPythonのfor文で一括処理する。
データはこんな感じ。今回はICC(2,k)を計算していく。
CSVファイルの説明
ID; 患者個々のuniqueな値
rater; 検者
data_1〜24; 実測データ
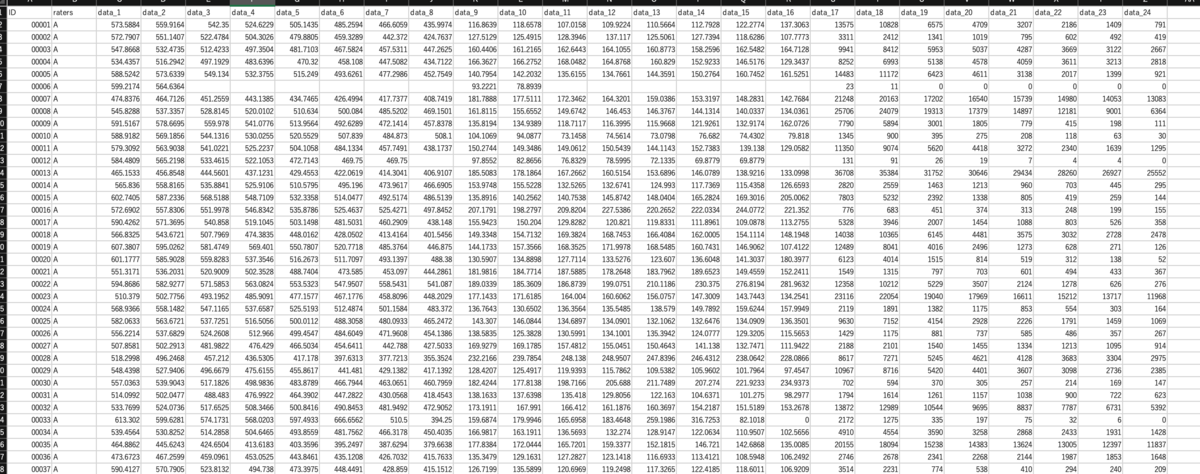
検者間のデータを縦に並べる。下にいくと検者Bとなる。
keyとなるmoduleは、”pingouin” という統計ツール.
pipでinstallしておく。(なお、当方はpip派。condaと混ぜるのはNG)
〜 pip install pingouin 〜
以下、実行のコード
〜 import os import numpy as np import pandas as pd import pingouin as pg ws = "ワークスペースとなるフォルダパスを指定" os.chdir(ws) print(os.getcwd()) path = "for_ICC.csv" #csvのpath df = pd.read_csv(path) colum_nm =list(df.columns.values) #colum nameを得ておく nm_length = len(colum_nm) #colum nameの長さ得ておく #appendの空箱の準備 value = [] icc_1_2 = [] p_value = [] IC_value= [] for x in range(2,nm_length ): #for 文をcolumの3番目から回す。(1番目はID,2番目はraterが入っている。) #列を一つずつ抽出してdataframe化して、"pg.intraclass_corr"の引数へ渡す tmp_colum_nm = colum_nm[x] ratings =df[tmp_colum_nm] raters =df["raters"] targets =df["ID"] data = pd.DataFrame({'targets':targets, 'raters':raters, 'ratings':ratings}) #ここで計算 icc = pg.intraclass_corr(data=data, targets='targets', raters='raters', ratings='ratings') # 各値を抽出する icc_1_2_val= icc.iloc[2,2] p_val= icc.iloc[2,6] IC= icc.iloc[2,7] # appendで格納していく value.append(tmp_colum_nm) icc_1_2.append(icc_1_2_val) p_value.append(p_val) IC_value.append(IC) # dataframe化 value = pd.Series(value) icc_1_2 = pd.Series(icc_1_2) p_value = pd.Series(p_value) IC_value = pd.Series(IC_value) #dataframeを縦に結合 tmp_df = pd.concat([value,icc_1_2,p_value,IC_value],axis=1) #dataframeをcolumnの名前を編集 tmp_df = tmp_df.rename(columns={0:'value',1:'ICC(1,2)',2:'p_value',3:'IC'}) #csvを出力 tmp_df.to_csv('ICC1_2.csv', header=True, index=True) 〜
この方法でどんだけ多いデータでも簡単にICCを計算できる。
出力したcsvを整形してこんな感じ

検者2人のデータが別のcsvであった場合、dataframeの結合して変数名を編集してからでも機能するとおもいますが、ざっくりコピペでいけるのでcsvのは先に手作業が楽かもです。